第三节课程
- slide: https://15445.courses.cs.cmu.edu/fall2022/slides/03-storage1.pdf
- note: https://15445.courses.cs.cmu.edu/fall2022/notes/03-storage1.pdf
各级存储及其访问时间
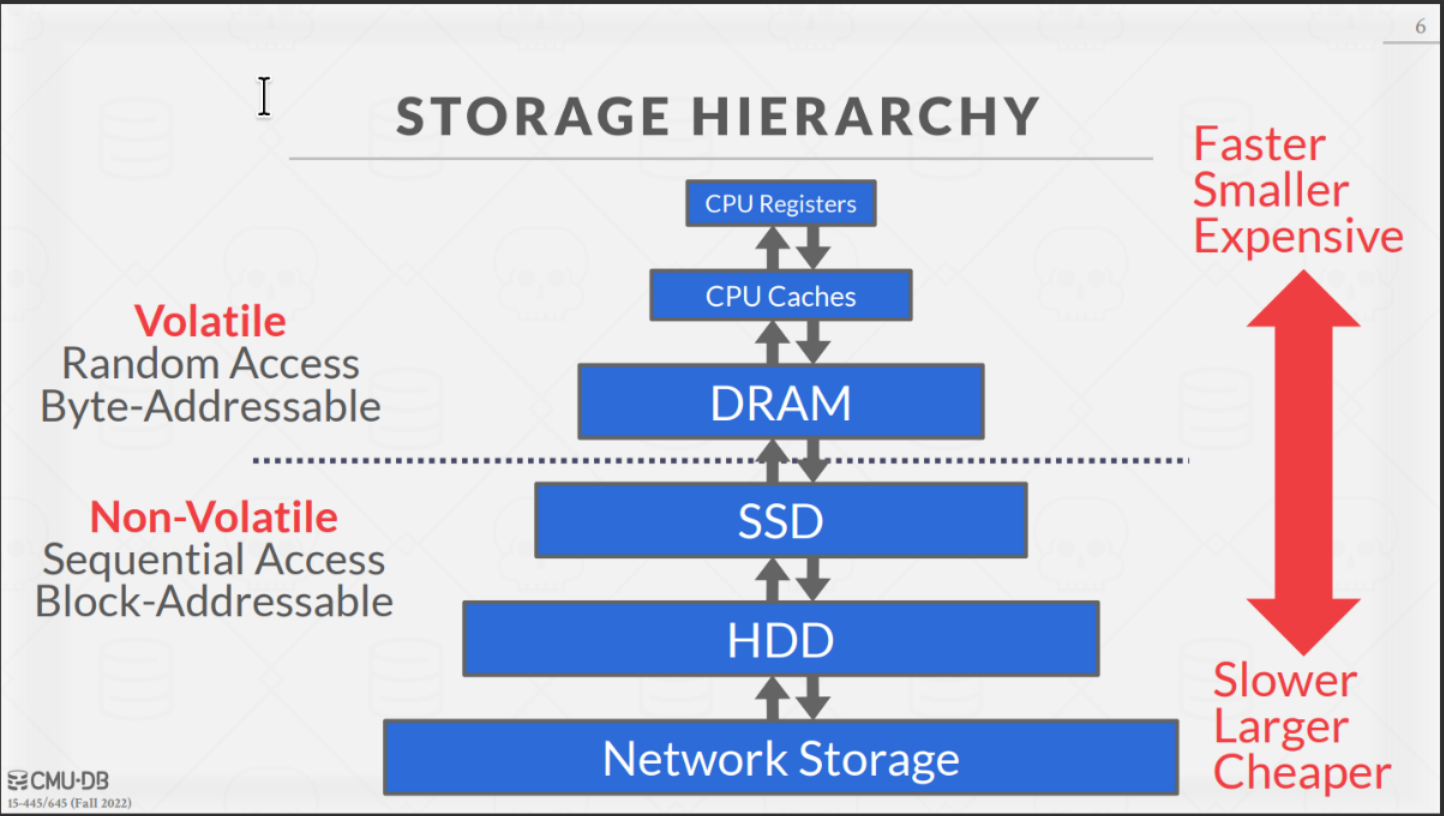

访问时间来源: https://colin-scott.github.io/personal_website/research/interactive_latency.html
随机访问要比顺序访问慢很多,所以很多时候 DBMS 会尽量减少随机访问,争取做到顺序访问。
读写磁盘的代价是昂贵的,DBMS 应该妥善管理读写,来避免卡顿或性能下降。
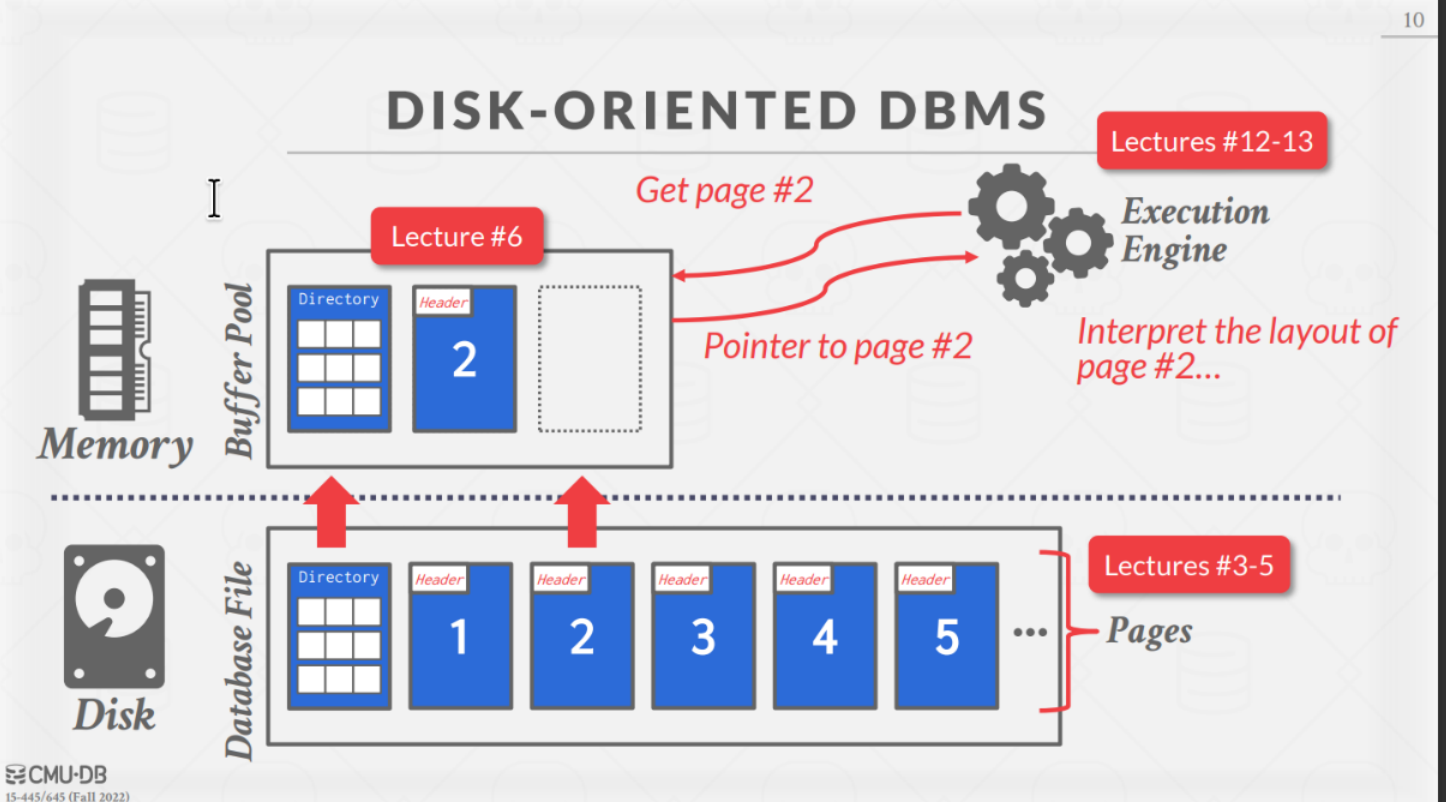
Disk-Oriented DBMS
数据库存储在磁盘上,数据库文件中的数据以 page 的形式组织和存储。第一页往往是特殊页,例如 header page,directory page,存储元数据的 page 等。
为了操作数据,DBMS 需要将数据从磁盘读取到内存中,然后再进行操作。在 DBMS 中有一个 buffer pool manager 负责管理磁盘和内存之间的数据传输。
当执行引擎需要某个页时,会向 buffer pool manager 请求,如果该页已经在内存中,则直接返回;否则,buffer pool manager 会从磁盘中读取该页,并将其放入内存中,然后将指针返回给执行引擎。
为什么不把内存管理交给操作系统?
DBMS 可以使用 mmap 等技术将文件映射到内存中,操作系统会自动的从磁盘将需要的 page 移到内存中,也能够自动的将内存中的 page 写回磁盘。
但是将内存管理交给 OS 会有一些问题:
-
事务安全性:OS 可能会把脏页(已经被修改了的页)写回磁盘
-
I/O Stalls: 数据库不知道哪个页在内存中,当需要某个页时,可能会发生 I/O Stall,即线程等待磁盘读取数据
-
错误控制:其他进程对文件的访问会造成 SIGBUS 错误,DBMS 需要处理这些错误
-
性能问题:OS data structure contention. TLB shootdowns.
提示-
OS 数据结构争用 (OS data structure contention):
-
这指的是在操作系统内部,不同线程或进程之间共享的数据结构(例如锁、队列、表格等)的竞争问题。当多个线程或进程同时访问这些数据结构时,可能会发生冲突,导致性能下降或不一致的结果。解决这种争用通常需要使用同步机制,例如互斥锁或信号量。
-
-
TLB shootdowns:
- TLB(翻译后查找缓冲区)是一个缓存,用于将虚拟内存地址转换为物理内存地址。当处理器更改地址的虚拟到物理映射时,它需要通知其他处理器将其缓存中的映射无效化。这个过程被称为“TLB shootdown”(TLB 清除)。
- 在操作系统中,如果一个可能存在于 TLB 中的映射变得过时(由于内存映射更改),操作系统会将其从本地 TLB 中清除,以恢复一致性。同时,操作系统会通过发送处理器间中断(IPI)来指示可能在其 TLB 中存储该映射的远程核心执行相同操作。远程核心根据发起核心提供的信息刷新其 TLB,并在完成后报告回来。TLB 清除可能需要微秒级的时间,导致明显的减速。
- 为了避免 TLB 清除的延迟,程序员被建议不要使用内存映射,不要取消映射,甚至不要构建多线程应用程序。
-
同时也有一些方法可以解决上述问题:
- madvise:告诉 OS 你想要读取的页
- mlock:锁定页,防止被换出
- msync:将内存中的页写回磁盘
有一些 DBMS 使用了 mmap,有一些只使用了一部分,有一些完全不用。

Andy 认为:
对于内存管理,数据库能做的比操作系统更好:
- 以正确的顺序将脏页写回磁盘
- 更专业的读取策略
- 缓存替换策略
- 线程管理
数据库存储
导向问题:
- DBMS 如何将数据库放到文件中,是如何组织的?
- DBMS 如何管理内存,如何从磁盘中读取和写入数据?
文件存储形式
DBMS 将会以专有的格式把数据库存储在一个或者多个文件中,通常来说,一种 DBMS 的文件格式是专有的,不同的 DBMS 之间的文件格式是不兼容的。但是有一些开源的文件格式,志在成为通用的文件格式,例如 Apache Parquet。但是对于高性能的数据库来说,通常会使用专有的文件格式。
早期的 DBMS 还会使用专有的文件系统,但是在今天,DBMS 通常��会使用现有的文件系统。
存储管理
storage manager 负责管理数据库文件, 有些 storage manager 有自己的调度器,可能会做些顺序读取,批量处理等优化。
storage manager 会将数据组织成 page。storage manager 会跟踪 page 的读取和写入,跟踪空闲的 page 等。
页
page 通常是一个固定大小的数据块:
- 能包含 tuples, indexes, metadata, log records 等
- 大多数 DBMS 不混合存储不同类型的数据,即一个 page 只存储一种类型的数据,例如只存储 tuples,只存储 indexes 等
- 一些 DBMS 会要求 page 自包含,即本 page 有关的信息都放在本 page 中。
每个页面都会有个独特的 id,DBMS 使用一个中间层将 id 映射到物理位置。
有三种不同的 page 概念:
- hardware page:磁盘上的数据块,通常是 4KB
- OS page:操作系统的数据块,通常是 4KB
- Database page:DBMS 的数据块,通常是 512B - 16KB
hardware page 是存储设备能原子性写入的最小数据块,原子性指的是要么全部写入,要么失败返回错误。
不同数据块的 page 大小:

一些企业级的数据库(oracle, DB2)往往能自己调节 page 大小,来应对不同的情况。
大的 page size 会减少 I/O 次数,但是大于 4KB 的 page size, hardware 无法保证原子性写入,需要 DBMS 自己实现原子性。
小的 page size 的好处是减少内存浪费?我能想到的只有这一点。
Page Storage Architecture
不同的 DBMS 有不同的 page 组织方式:
- Heap File Organization: 一堆页面,数据是未排序的,数据可以放在任何位置
- Tree File Organization
- Sequential / Sorted File Organization (ISAM)
- Hashing File Organization
往后只讲了 Heap File Organization,其实三种是什么不清楚
一般会有一个 page directory,记录 page 的位置,这样可以快速找到 page。
Page Header
每个 page 都有一个 header,header 通常用来存储一些元信息:Page Size, Checksum, Version, Transaction Visibility, Compression Info 等等
一些 DBMS 还会要求 page 自包含(eg. Oracle)。(没太明白具体怎么做的,大概能实现的功能时恢复时即使表的元信息丢失了,通过 page 也能恢复部分数据)
Page Layout
组织 page 中数据的两种方式:
- Tuple-oriented
- Log-structured (下节课)
Tuple Storage
最常见的 layout 是 slotted page, 即 page 中有一个 slot array, 通过 slot array 可以找到 tuple 真实的位置。
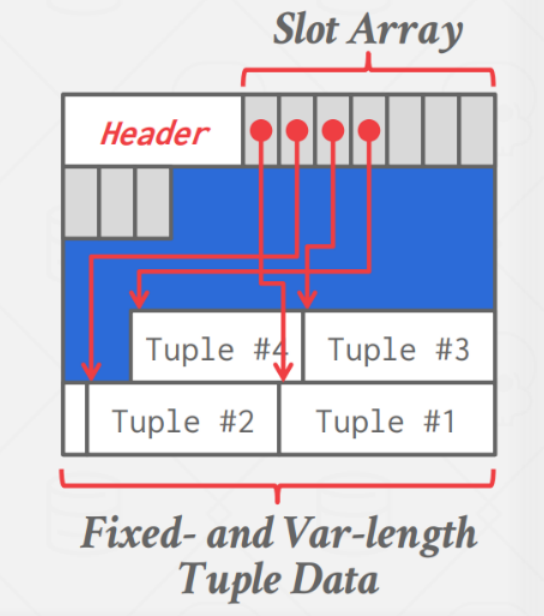
tuple 都是倒着开始存储的,这样的好处是如果 tuple 是变长的,倒着生长时如果 slot 数组和 tuple 相遇,就说明 page 满了。
当一个 tuple 被删除时,有些 DBMS 会移动其他 tuple 来保证中间没有空隙,有些就不会移动,只是标记为删除。有些 DBMS 还会有一个用于清理无用 tuple 的工具。
Record ID
每个 tuple 都有一个独特的 id, 一般是 page id 和 slot id/offset 的组合。
例如 Postgre 中的 ctid, MySQL 的 rowid,SQLLite 的 rowid 等等
SELECT ctid, * FROM table;
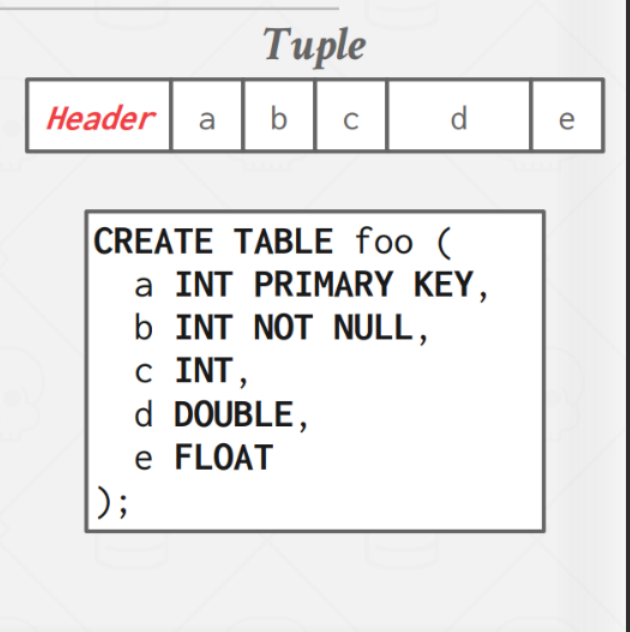
Tuple Layout
每个 tuple 也有一个 header,用于存储一些元信息,例如:
- 可见性,用于 并发控制
- BitMap,用于 NULL 值

属性一般是按建表顺序存储的,
Denormalized Tuple Data
有些 DBMS 可以 pre join (physically denormalize)相关的 tuple,可以减少 IO 次数,但是会增加更新的代价。
| 建表 | 存储 |
|---|---|
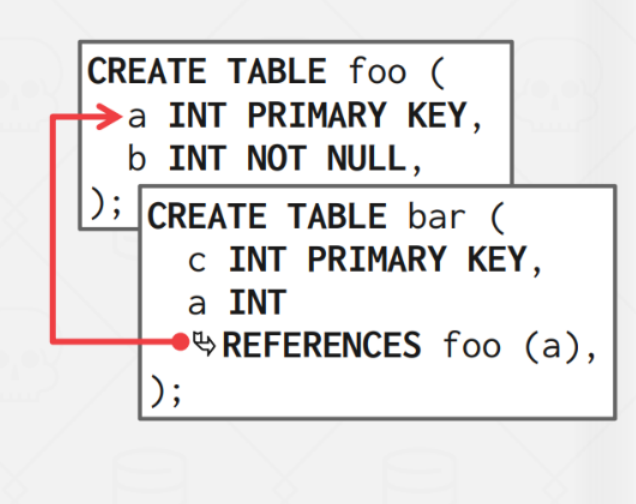 | 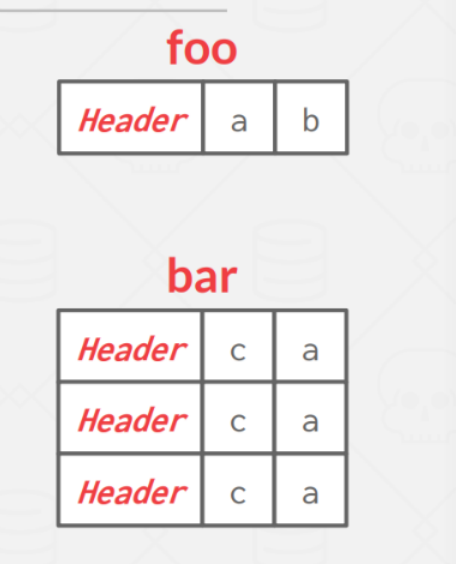 |