第二节课程
Slide: https://15445.courses.cs.cmu.edu/fall2022/slides/02-modernsql.pdf Notes: https://15445.courses.cs.cmu.edu/fall2022/notes/02-modernsql.pdf
数据准备
CREATE TABLE student (
sid INT PRIMARY KEY,
name VARCHAR(16),
login VARCHAR(32) UNIQUE,
age SMALLINT,
gpa FLOAT
);
CREATE TABLE course (
cid VARCHAR(32) PRIMARY KEY,
name VARCHAR(32) NOT NULL
);
CREATE TABLE enrolled (
sid INT REFERENCES student (sid),
cid VARCHAR(32) REFERENCES course (cid),
grade CHAR(1)
);
INSERT INTO student (sid, name, login, age, gpa) VALUES
(53666, 'Kanye', 'kayne@cs', 39 ,4.0),
(53688, 'Bieber', 'jbieber@cs', 26, 3.9),
(53655, 'Tupac', 'shakur@cs', 26, 3.5);
INSERT INTO course (cid, name) VALUES
('15-445', 'Database Systems'),
('15-721', 'Advanced Database Systems'),
('15-826', 'Data Mining'),
('15-823', 'Advanced Topics in Databases');
INSERT INTO enrolled (sid, cid, grade) VALUES
(53666, '15-445', 'C'),
(53688, '15-721', 'A'),
(53688, '15-826', 'B'),
(53655, '15-445', 'B'),
(53666, '15-721', 'C');
Aggregate
有以下五种基本的聚合函数:
- COUNT
- SUM
- AVG
- MAX
- MIN
COUNT
-- 查询 student 表中的记录数
SELECT COUNT(*) FROM student;
-- 查询 cs 专业的学生人数, % 表示任意字符任意次数
SELECT COUNT(login) FROM student WHERE login LIKE '%@cs';
SELECT COUNT(*) FROM student WHERE login LIKE '%@cs';
SELECT COUNT(1) FROM student WHERE login LIKE '%@cs';
SELECT COUNT(1+1+1) FROM student WHERE login LIKE '%@cs';
COUNT() 函数的参数可以是任意的表达式,例如 数学表达式、字段名、常量等。看起来很奇怪。
多个聚合函数
SELECT AVG(gpa), COUNT(sid)
FROM student WHERE login LIKE '%@cs';
DISTINCT 去重
-- 拥有不重复 login 的 cs 学生人数
SELECT COUNT(DISTINCT login)
FROM student WHERE login LIKE '%@cs';
GROUP BY
SELECT AVG(s.gpa), e.cid
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid
GROUP BY e.cid
这是一个较复杂的 SQL 语句,它的执行过程如下:

可以理解成,先将 enrolled 表和 student 表进行笛卡尔积(带上 WHERE 条件),然后根据 e.cid 进行分组,最后对每个分组进行聚合操作。
需要注意的是,在 SELECT 中的字段,如果不是聚合函数,那么它必须出现在 GROUP BY 中。
HAVEING
如果想要对 GROUP BY 的结果进行筛选,可以使用 HAVING 子句。
-- 这样的语句是可能是错误的,在PostgreSQL中会报错,MYSQL中不会报错
ELECT AVG(s.gpa) AS avg_gpa, e.cid
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid
GROUP BY e.cid
HAVING avg_gpa > 3.9;
-- 正确的写法,虽然写了两次 AVG(s.gpa),但对现代数据库来说,这并不会导致两次计算
SELECT AVG(s.gpa), e.cid
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid
GROUP BY e.cid
HAVING AVG(s.gpa) > 3.9;
聚合如何处理 NULL
这个不是 15445 的内容,但是在实际使用中,可能会遇到。
SUM,AVG,MAX,MIN 函数会忽略 NULL 值,而 COUNT 函数会计算 NULL 值。
如果一个字段中有 NULL 值,那么 COUNT(*) 和 COUNT(字段名) 的结果是不一样的。
COUNT(*) 会计算所有的记录数,而 COUNT(字段名) 会忽略 NULL 值。
String
方言
SQL 语言的方言很多,不同的数据库系统对字符串的处理方式也不尽相同。
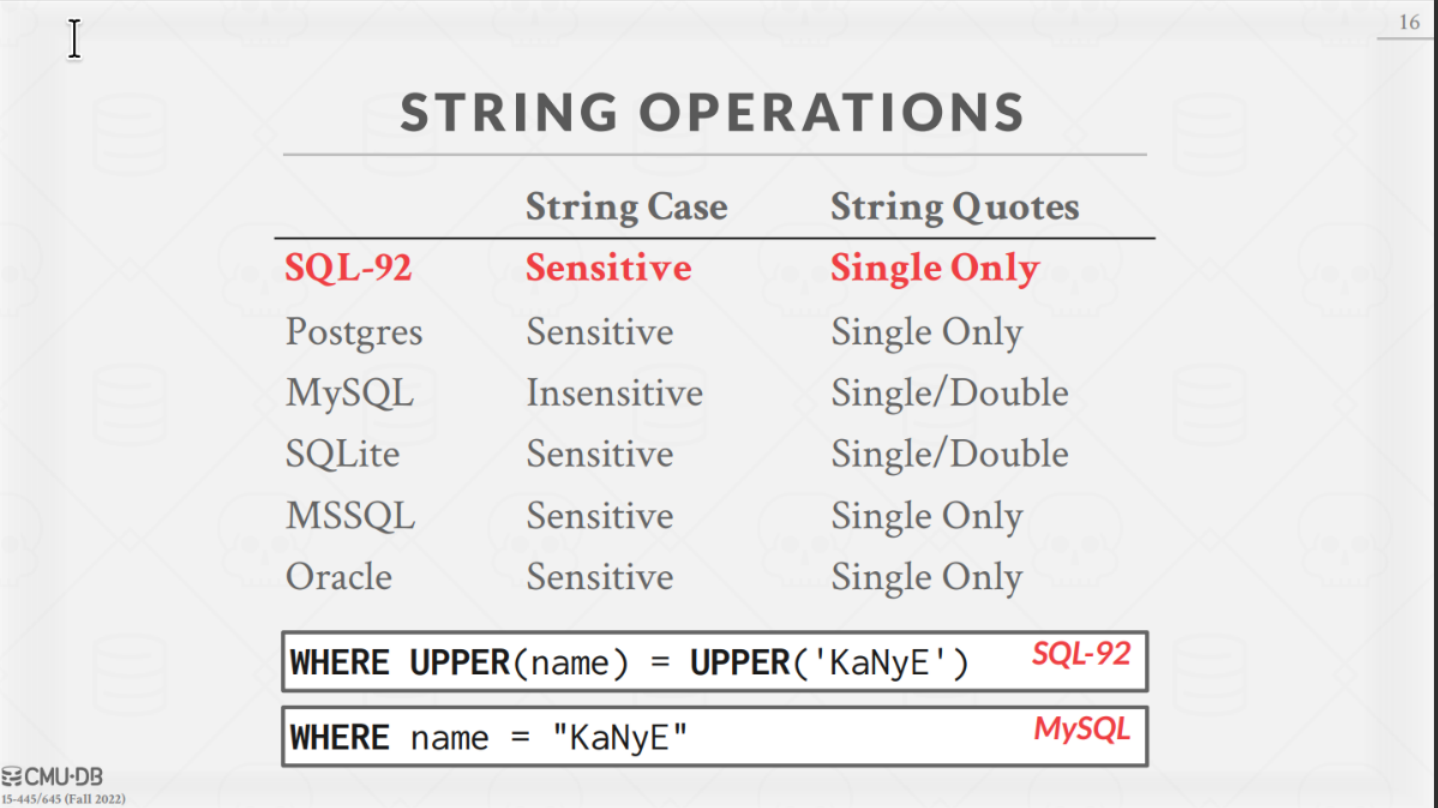
字符串操作
LIKE 是 SQL 中的模糊查询,% 表示任意字符任意次数,_ 表示任意字符一次。
同时还有 UPPER,LOWER,SUBSTRING 等函数。可以出现在 输出字段、WHERE 子句、ORDER BY 子句等。
Where 子句,也称为 Predicates, 翻译为谓词,述语。
字符串拼接:
SELECT name FROM student
WHERE login = LOWER(name) || '@cs'
SELECT name FROM student
WHERE login = LOWER(name) + '@cs'
SELECT name FROM student
WHERE login = CONCAT(LOWER(name), '@cs')
SELECT 'Andy' '' 'Andy'
DATE/TIME 操作
NOW(), CURRENT_TIMESTAMP函数返回当前时间。
SELECT NOW();
SELECT CURRENT_TIMESTAMP;
可以使用 DATE() 函数将时间戳转换为日期。
在不同的数据库系统中,日期时间的操作和结果可能会有所不同。
OUTPUT REDIRECTION 输出重定向
可以将查询结果输出到到新表中或者插入到已有的表中。
-- SQL-92
SELECT DISTINCT cid INTO CourseIds
FROM enrolled;
-- MYSQL
CREATE TABLE CourseIds (
SELECT DISTINCT cid FROM enrolled);
-- SQL-92
INSERT INTO CourseIds
(SELECT DISTINCT cid FROM enrolled);
OUTPUT CONTROL
可以使用 ORDER BY 对结果进行排序。
SELECT sid, grade FROM enrolled WHERE cid = '15-721'
ORDER BY grade;
默认排序是升序,可以使用 DESC 关键字进行降序排序。
SELECT sid, grade FROM enrolled WHERE cid = '15-721'
ORDER BY grade DESC;
可以指定多个 By 子句进行更复杂的查询
SELECT sid, grade FROM enrolled WHERE cid = '15-721'
ORDER BY grade DESC, sid ASC;
可以在 By 子句中使用任意的表达式
SELECT sid FROM enrolled WHERE cid = '15-721'
ORDER BY UPPER(grade) DESC, sid + 1 ASC;
可以使用 LIMIT 子句限制返回的结果数量
SELECT sid, name FROM student WHERE login LIKE '%@cs'
LIMIT 10;
可以使用 OFFSET 指定偏移量
SELECT sid, name FROM student WHERE login LIKE '%@cs'
LIMIT 20 OFFSET 10;
NESTED QUERIES 嵌套查询
嵌套查询是在一个查询中执行更复杂逻辑的一种方式,可以在其他查询中调用查询。嵌套查询通常很难进行优化。 外部查询的范围包含在内部查询中(即内部查询可以访问外部查询的属性),但反之则不成立。 内部查询可以出现在查询的几乎任何部分:
- SELECT 子句:
SELECT (SELECT 1) AS one FROM student;
- FROM 子句:
SELECT name
FROM student AS s, (SELECT sid FROM enrolled) AS e
WHERE s.sid = e.sid;
- WHERE 子句:
SELECT name FROM student
WHERE sid IN ( SELECT sid FROM enrolled );
Example: 得到所有选修了 15-445 课程的学生的名字。
SELECT name FROM student
WHERE sid IN (
SELECT sid FROM enrolled
WHERE cid = '15-445'
);
请注意,sid 的作用域取决于它在查询中的出现位置。 示例:找到至少选修了一门课程的最高 id 的学生记录。
SELECT student.sid, name
FROM student
JOIN (SELECT MAX(sid) AS sid
FROM enrolled) AS max_e
ON student.sid = max_e.sid;
嵌套查询结果函数:
• ALL • ANY • IN • EXISTS
SELECT name FROM student
WHERE sid = ANY (SELECT sid FROM enrolled WHERE cid = '15-445');
SELECT name FROM student
WHERE sid IN (SELECT sid FROM enrolled WHERE cid = '15-445');
Example: 查找没有学生参加的课程:
SELECT * FROM course
WHERE NOT EXISTS(
SELECT * FROM enrolled
WHERE course.cid = enrolled.cid
);
Window Functions 窗口函数
窗口函数是一个非常强大的 SQL 功能。
以下是 NewBing 生成的窗口函数介绍:
- 什么是窗口函数?
-
窗口函数,也称为 OLAP 函数(Online Analytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
-
窗口函数的基本语法如下:
<窗口函数> OVER (PARTITION BY <用于分组的列名> ORDER BY <用于排序的列名>) -
窗口函数的位置可以放以下两种类型的函数:
- 专用窗口函数,例如 RANK、DENSE_RANK、ROW_NUMBER 等。
- 聚合函数,如 SUM、AVG、COUNT、MAX、MIN 等。
- 如何使用窗口函数?
-
让我们通过实例来介绍几种窗口函数的用法。
-
专用窗口函数:RANK
- 假设我们有一个班级表,想要在每个班级内按成绩排名。以下是示例 SQL 语句:
SELECT *, RANK() OVER (PARTITION BY 班级 ORDER BY 成绩 DESC) AS ranking
FROM 班级表- 这将为每个班级内的学生按成绩排名。
-
其他专用窗口函数:DENSE_RANK 和 ROW_NUMBER
- DENSE_RANK 和 ROW_NUMBER 与 RANK 类似,但它们在处理并列名次时有不同的行为。
- 聚合函数作为窗口函数
- 聚合函数也可以作为窗口函数,只需将聚合函数放在窗口函数的位置,并指定聚合的列名。
- 例如,以下 SQL 语句计算每个学生的累计总分、平均分、人数、最高分和最低分:
SELECT *,
SUM(成绩) OVER (ORDER BY 学号) AS current_sum,
AVG(成绩) OVER (ORDER BY 学号) AS current_avg,
COUNT(成绩) OVER (ORDER BY 学号) AS current_count,
MAX(成绩) OVER (ORDER BY 学号) AS current_max,
MIN(成绩) OVER (ORDER BY 学号) AS current_min
FROM 班级表
Common Table Expressions (CTE)
又一个强大的功能,相当于创建一个临时表?
WITH cteName (col1, col2) AS (
SELECT 1, 2
)
SELECT col1 + col2 FROM cteName;
-- 错误的
WITH cteName (colXXX, colXXX) AS (
SELECT 1, 2
)
SELECT colXXX + colXXX FROM cteName
-- 正确的
WITH cteName (colXXX, colXXX) AS (
SELECT 1, 2
)
SELECT * FROM cteName
-- 通过 CTE 找到最大的 sid 对应的学生名字
WITH cteSource (maxId) AS (
SELECT MAX(sid) FROM enrolled
)
SELECT name FROM student, cteSource
WHERE student.sid = cteSource.maxId
-- 打印 1 到 10
WITH RECURSIVE cteSource (counter) AS (
(SELECT 1)
UNION ALL
(SELECT counter + 1 FROM cteSource
WHERE counter < 10)
)
SELECT * FROM cteSource